3.1 Probabilistic Nature
To understand the "Silicon-based Employee," the first and most subversive trait we must grasp is its Probabilistic Nature.
When discussing the "probabilistic" nature of AI, we must first avoid a common mental trap: comparing it with the "Deterministic Software" we are familiar with. Traditional software is like a precise ruler; if you input 2+2, it will always give you 4. If you click save, the file will definitely be saved to the specified path, otherwise, it is a program error. This is a black-and-white world of 0s and 1s, where "uncertainty" equates to "defects."
But AI is not a ruler, nor is it a calculator. Its working principle is more like the "judgment" and "decision-making" we see everywhere in our daily lives.
For example, when you use a search engine to search for "weather in Shanghai today," you don't expect it to return a meteorological report accurate to the minute 100% of the time. You expect it to most likely provide you with an accurate and useful weather forecast page or information summary. When it returns a marketing page unrelated to the weather, you might feel it is "inaccurate," but you won't think this is a "program crash."
This probabilistic nature of AI stems from the internal structure of its models—they are formed by learning statistical laws from massive amounts of data. They cannot "understand" the causal relationships of the world like humans do, but generate content by "predicting" the maximum likelihood of the next word, the next piece of code, or the next pixel. This results in its output not being absolutely reliable, but carrying a "tail of probability." We call this "Hallucination," where it might fabricate facts out of thin air or produce logical loopholes.
So, is this probabilistic nature of AI a "blessing" or a "curse"? To answer this question, we should not compare it with the certainty of machines, but with the predecessor of the "Silicon-based Employee"—the Human Employee.
When we switch our perspective to compare with "Carbon-based Employees," the probabilistic nature of AI presents a surprising manageability and reliability. The output of a human employee is deeply influenced by countless unquantifiable "hidden parameters": whether they slept well last night, arguments with family, career anxiety about the future, subtle interpersonal relationships in the office, or even just a bad mood on Monday morning. These factors together constitute an almost unpredictable "black box," causing human "uncertainty" to be deep, non-systematic, and often catastrophic.
Wang Wei (the senior engineer we mentioned in the previous section) might have stayed up all night because his child was sick, leading to irritability, buggy code, and even arguments with colleagues during team meetings. His "uncertainty" is chaotic, difficult to predict, and can spread to the entire team through the "emotional contagion" effect. Managing him requires employing psychology, organizational behavior, and even "office politics"—a series of complex and often ineffective "arts."
In contrast, the "uncertainty" of AI is completely different. It doesn't have "Monday blues" and won't perform abnormally due to personal crises. Although its errors exist, they are often systematic, predictable, and even precisely reproducible under the same conditions. When AI produces "hallucinations," it's not because it's in a bad mood, but because the data it learned was insufficient, or the reasoning path had a statistical bias.
Therefore, we must establish a new management cognition: AI's "uncertainty" is a technical problem, while human "uncertainty" is a management problem. The former can be constrained and mitigated through engineering means such as system optimization, parameter tuning, redundancy design, and verification mechanisms; while the latter requires complex "arts." From this perspective, the probabilistic nature of AI is not a curse of management, but rather reduces complex, uncontrollable human management problems into a purer, more controllable engineering challenge. This is the true cornerstone for us to harness the AI legion.
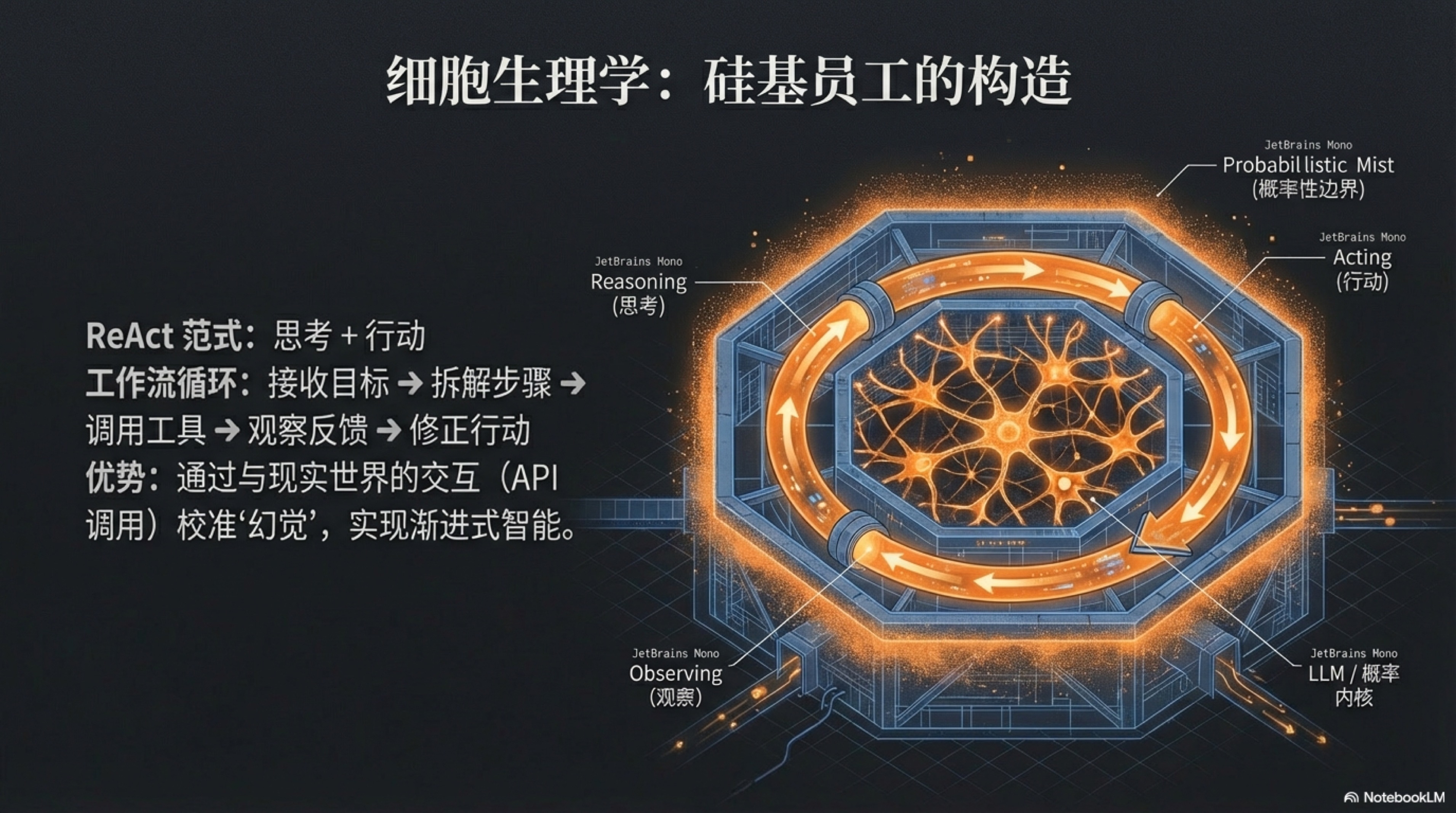
The question then arises: If our "employees" are born with a "tail of probability," how can we entrust them with heavy responsibilities and let them independently solve truly complex problems? The answer lies in a core working paradigm called ReAct.
ReAct is an abbreviation for "Reasoning" and "Acting." It cleverly mimics the basic logic of humans when solving complex problems: Think, then Act, then Observe the results, then Think again and adjust direction. By weaving together the two previously separated actions of "thinking" and "acting," it endows AI with a powerful capability close to a "sense of intelligence."[^1][^2][^3]
Let's use a more detailed example to dismantle this process. Suppose you command an AI: "Plan a five-day family trip to Paris for me, budget 30,000 RMB, departing from Shanghai, requiring special gourmet experiences."
An ordinary large model not using ReAct would likely output a seemingly complete travel itinerary all at once. It might fabricate flight numbers, hotel names, or even non-existent Michelin restaurants out of thin air. Everything looks "seamless" until you try to book, only to find it was just a "beautiful hallucination." Because it lacks interaction with the real world and self-verification.
However, an agent using the ReAct paradigm would work step-by-step like an experienced personal assistant:
- Reasoning: "Okay, the goal is a 5-day family trip to Paris, budget 30k, departing from Shanghai, including food. I first need to confirm the core costs—flights and accommodation. Where to start? Check round-trip flights from Shanghai to Paris first, as this directly affects the budget and dates."
- Acting: (Agent calls
search_flights_apitool) "Search for 5-day round-trip flights from Shanghai Pudong (PVG) to Paris Charles de Gaulle (CDG), economy class, family of three, dates within the next two months." - Observation: (API returns result: Found that the lowest round-trip ticket for three people within the next two months is 25,000 RMB, and dates are not fixed, might need longer time to find suitable flights, or finding this budget is very tight including taxes.)
- Reasoning: "Flight prices are higher than expected, taking up the bulk of the budget. If only 5,000 remains for accommodation, dining, and activities, it definitely cannot satisfy 'special gourmet experiences.' I need to evaluate whether to adjust dates to strive for lower airfare, suggest the user increase the budget, or look for other European cities? Before deciding, I need to know the approximate cost of hotels. At the same time, I should inform the user of the current flight price situation."
- Acting: (1. Call
search_hotels_apitool) "Search for mid-range hotels in downtown Paris suitable for families, 5 nights. 2. Meanwhile, prepare to feedback flight information to the user." - Observation: (API returns result: Average price for 5 nights in downtown Paris hotels is around 10,000 RMB. Meanwhile, user wait time is too long, might get impatient.)
- Reasoning: "Based on flight and hotel estimates, a 5-day Paris trip with 30k budget and gourmet food is almost impossible. I need to communicate with the user in time. I can propose several alternatives: A. Increase budget; B. Reduce days; C. Consider other cities with lower costs. Give the suggestion that best fits the current context first."
- Acting: (Agent generates feedback) "Hello, I have preliminarily queried the 5-day family flights and hotels from Shanghai to Paris. Currently, the lowest round-trip ticket for three is about 25k, and 5 nights in a Paris hotel is about 10k. The total has exceeded your 30k budget. To achieve the special gourmet experience, I suggest you consider: 1. Increasing the budget to 45k-50k; 2. Shortening the itinerary to 3 days, but the gourmet experience might be limited; 3. Considering cities with more friendly prices like Lisbon, Portugal. How would you like to adjust?"
This "Think-Act-Observe-Re-think-Re-act" loop is the essence of the ReAct paradigm. It forces AI to break down grand, vague goals into a series of executable and verifiable micro-steps. More importantly, by interacting with the external world (such as APIs, databases, web pages) in real-time through "Acting," AI can obtain real, immediate information to "calibrate" its "Reasoning," thereby greatly reducing the phenomenon of "hallucinations" created out of thin air, and improving the quality and reliability of decisions.
This mode endows AI with a "progressive intelligence"—it does not give the answer perfectly at once, but gradually approaches the optimal solution through constant trial and error and correction. It makes the AI's decision-making process no longer an incomprehensible "black box," but a series of clear, traceable, and intervenable steps. This ability to "think while doing, do while thinking" like a human is the source of the "sense of intelligence" in agents, and also the premise for us to trust and delegate complex tasks to it.
It must be clarified that the ReAct paradigm aims to improve the navigation and error correction ability of a single agent when performing specific tasks. It solves the problem of "how do I complete this task step by step." This is a mechanism belonging to a different level from the PDCA (Plan-Do-Check-Act) cycle we will discuss in the second half of this book, which drives the entire organization to learn and evolve from long-term success and failure. ReAct gives the individual the basic skills to "survive" and "solve problems" in a complex environment, while PDCA is the strategic engine that allows this individual and even the entire organization to "evolve" and "become stronger."
[^1]: The seminal work on the ReAct paradigm can be found in Google Research's official blog, which details how ReAct improves Agent performance in complex tasks by combining reasoning capabilities in language models with external action tools. Google Research, "ReAct: Synergizing Reasoning and Acting in Language Models". Link [^2]: A paper jointly published by Princeton University and Google further verified the effectiveness of the ReAct framework, demonstrating its significant performance improvement and error reduction in tasks such as QA, fact-checking, and decision-making compared to pure language models. Princeton University, "REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS". Link [^3]: The original academic paper on ReAct provides deeper technical details and experimental data, which is of great value for understanding its internal working mechanisms and evaluation standards. OpenReview, "REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS". Link