Google 搜索与 SEO 指南
摘要
本文系统梳理了 Google 搜索的工作原理与 SEO 实践:从 Crawling、Indexing、Serving 三阶段拆解核心流程,说明 AI(如 BERT、RankBrain、MUM)在理解语义与排序中的作用,并澄清 Gemini 与搜索系统的关系;同时覆盖 AEO/GEO/SEO 的共性逻辑,抓取预算的影响因素与优化方向,图片/视频的索引要点与结构化数据最佳实践,以及多语多区域站点的本地化策略(含 hreflang 与 canonical)。最后,附上 Honest Results Policy、官方报表模板、Search Console 气泡图分析与 Google Trends 等工具与案例,便于排错和持续优化。
Google 搜索如何运作
共 7515 字阅读需 16 分钟
Google 搜索如何运作(1)
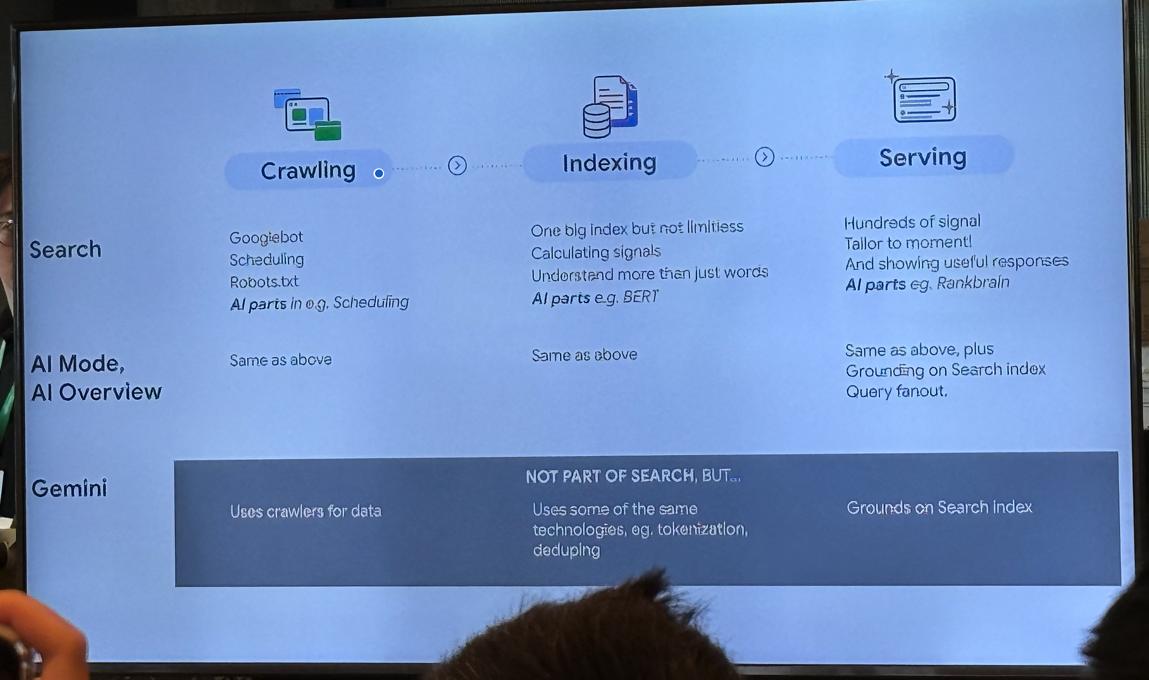
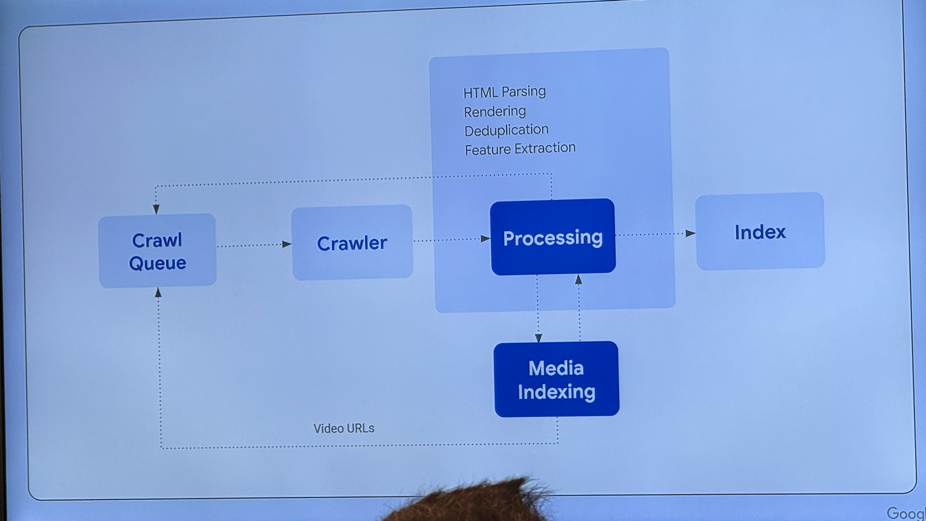
Google 搜索系统通过 “Crawling → Indexing → Serving” 三阶段完成网页抓取、理解与结果呈现。AI(如 BERT、RankBrain)在其中帮助理解语言和优化排序。而 Gemini 虽非搜索功能,但共用相同的底层技术和索引基础。
1. Crawling(检索)
作用:让搜索引擎获取最新网页内容。
由 Googlebot 完成网页抓取
受 Scheduling(抓取调度) 与 Robots.txt 规则控制
AI 的参与:在调度(Scheduling)中利用 AI 决定何时抓取、抓哪些页面
每个网站的检索频率是不同的,取决于网站反应速度、大致内容质量、潜在报错等信号
2. Indexing(建立索引)
作用:理解网页内容、提取信号并构建可被检索的数据库。
Google 建立一个巨大的索引数据库(但非无限)
包含 信号计算(Calculating signals)
不仅理解单词,还要理解语义与上下文
AI 的参与:使用 BERT 等模型提升语义理解
Statistical models
统计模型在 Google 已使用了 超过 20 年
擅长捕捉垃圾信息(spam)
最初用于解决“Did you mean:”(你是不是想找:)功能
简言之:统计模型擅长规则化、基于历史数据的搜索优化和纠错。
BERT(Bidirectional Encoder Representations from Transformers)
是一个 深度学习模型(deep learning model)
使用 transformers 来理解句子中单词的上下文
通过考虑整句话的单词序列而不是单个处理单词,来更好理解含义
简言之:BERT 擅长理解自然语言的语境,提升搜索结果的相关性。
3. Serving(提供搜索结果)
作用:在用户查询时返回最精准、最相关的搜索结果。
AI 的参与:使用 RankBrain 等模型优化结果排序与相关性
综合数百个信号(Hundreds of signals)
- 网页:文字、链接、段落等
- 图片:解析度、色彩、相关文字等
- 新闻/文章:新鲜度、原创性、多元性等
- 区域:位置、类型、评分、评论、营业时间等
- 视频:语言、语音转录的文字等
根据用户的搜索意图与时机提供最有用的结果
RankBrain
作用: 帮助谷歌理解搜索查询的含义以及它们与网页的关联。
主要功能: 解读用户搜索(尤其是新的或不常见的查询)背后的意图,并将其与最相关的结果进行匹配。
MUM
- 作用: 擅长跨不同模态(如文本、图像、音频和视频)理解信息。
- 主要功能:
- 多语言性: 能处理超过75种语言的信息。
- 解答复杂问题: 能够为复杂的问题提供更全面、更细致入微的答案。
4. Gemini 与 Search 的关系
- Gemini(AI 模型)并非搜索系统的一部分,但使用与搜索相同的技术,如:
- 数据抓取(Crawlers)
- 分词(Tokenization)
- 去重(Deduplication)
- 依托搜索索引(Search index) 作为其知识基础(Grounding on Search Index)

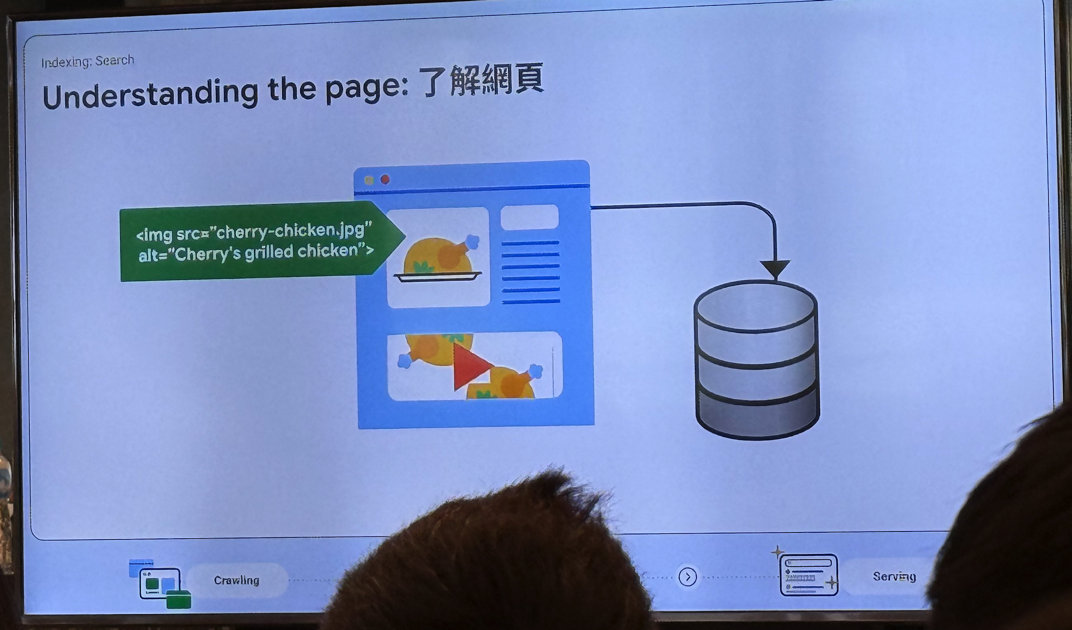
1. Crawling(检索)


图片、视频都需要按格式命名,方便爬取
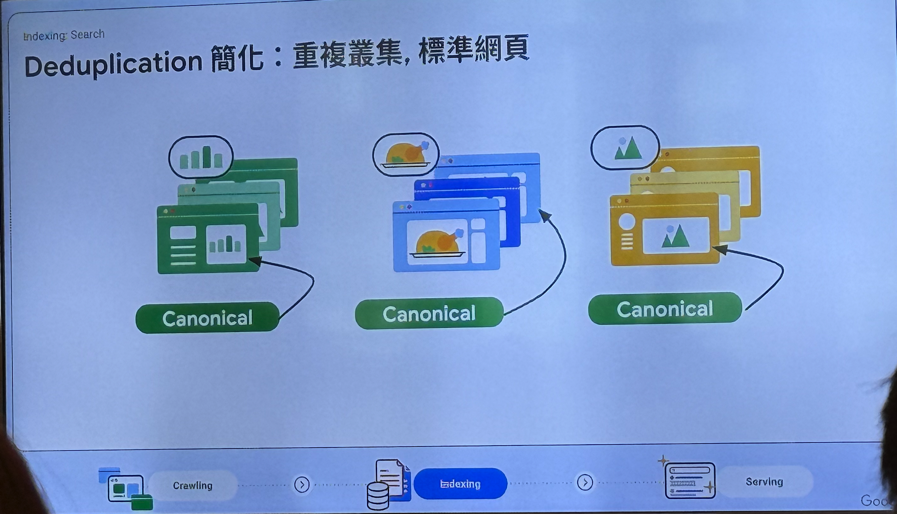
2. Indexing(建立索引)
当出现相似内容时,利用canonical告诉搜索引擎真正重要的那个页面是哪个(权威/原始版本的URL),其他相似或重复内容的页面应算其副本且不要单独收录或分散权重

3. Serving(提供搜索结果)
- 搜索引擎会忽略解读a, the, of等无含义的冠词和介词
- 不同语言的有不同的处理模型,比如中文的炸鸡会分别搜“炸”和“鸡”



AEO, GEO, SEO?
底层逻辑都是SEO,本质是提供高质量内容换取高排名。
- 共同基础 (SEO): GEO 和 AEO 都是建立在 SEO 基础之上的。一个没有做好基础 SEO(如网站速度、移动友好性)的网站,很难在 GEO 或 AEO 上取得好成绩。
- 用户意图为王: 三者都极度依赖对“用户意图”的深刻理解。它们都试图在用户寻找信息或解决方案时,提供最相关、最优质的内容。
- 内容质量核心: 无论是哪种优化,高质量、原创且相关的内容始终是成功的基石。
- 最终目的: 三者是一致的:提高在线可见性,吸引相关的目标用户,并最终实现业务目标(如获取流量、产生潜在客户或完成销售)。

高质量内容四大支柱
1. 投入心力(Effort)
是否花心思创作可读性高的内容,假如完全用AI生成的内容评分会很低
2. 原创性(Originality)
内容是否独特,其他网站无法提供。相似的内容,越早发布越有优势。内容呈现要精美,不要有量产感,需表达个人意见和看法。
3. 才能/技能(Talent or Skill)
创作这些内容需要达到何种程度的才能和技能,对所说事物的心得、理解、一手经验
4. 准确性(Accuracy)
内容中事实的准确程度,不要为了原创而虚构
高质量内容定义 - EEAT
其中可信度是最重要的
1. Experience(经验)
2. Expertise(专业知识)
3. Authoritativeness(公信力)
4. Trust(可信度)
低质量内容定义
Spam policy:https://developers.google.com/search/docs/essentials/spam-policies
Spam updates: https://status.search.google.com/products/rGHU1u87FJnkP6W2GwMi/history
1. Cloaking (障眼法/伪装)
定义:向用户和搜索引擎呈现不同的内容。
目的:操纵搜索排名并误导用户。
2. Doorways (门页/桥页)
定义:创建专门针对特定、相似搜索查询排名的网站或页面。
特点:这些页面会将用户引导至并非最终目的地、用处不大的中间页。
3. Scraped Content (采集的内容)
定义:网站的大部分内容是从其他地方“抓取”(Scraped)来的。
特点:网站本身没有提供额外的服务或内容,无法为用户提供附加价值。
4. Link Spam (链接垃圾)
定义:谷歌将链接作为判定网页相关性的重要因素。任何意图操纵谷歌搜索结果排名的链接都可能被视为链接垃圾。
5. Hacked Content (被黑客入侵的内容)
定义:由于网站存在安全漏洞,导致内容未经许可被放置在网站上。
关键点:清理工作很困难(可能需要6-18个月去恢复),预防才是关键 (goo.gle/hack-tips),根据6大原则去做就无需担心。



《Google 搜索品质评估人员指南》
 PDF
PDF
Google 搜索生态的持续进化
人类的好奇心好比婴儿,每天都有15%的搜索内容是全新的,搜索生态需持续进化以满足用户需求
需评估是否全站内容都是以人为本(写给人看),而非单个页面
Google Search核心更新:https://developers.google.com/search/blog
1. 持续测试
有一批SEO志愿者会为Google和其他搜索引擎持续评估内容和需求,提供建议
2. 持续优化SERP
提高内容的可读性,配以精准的配图和视频,多元呈现内容
3. 持续解决不同用户不断变化的需求
有的用户希望得到链接自己调查、有的希望得到一个快答案、有的希望提供完整调查结果,Google会全方面满足用户需求
4. 奖励高质量内容
只是喂给搜索引擎爬的内容得不到高评分
5. 流量结构会波动
并非越久越占优势,创造更多流量机会给新站点

本地化索引 Localization
1. 相同内容的聚合
- 当主要内容相同时,页面会“聚合” (cluster)。
- 包括那些仅有样板文字 (boilerplate-only)(如页眉、页脚)进行本地化的情况
- 巧妙的地理位置重定向 (geo-redirecting) 通常也会导致页面聚合
- 针对以上问题,使用 hreflang 备用标签 (hreflang alternates)
(注:hreflang 标签的作用是告诉谷歌,这些内容相似的页面是针对不同语言或地区用户的,不应将它们视为重复内容。)
2. 官方建议
- 使用重定向 (redirects) 来告知Google网站进行了改版。
- 向Google发送有意义的 HTTP 结果代码 (meaningful HTTP result codes)。
- 检查 rel=canonical 规范链接
- 使用 hreflang 链接来帮助Google处理本地化内容
- 向论坛 (forums) 报告网站被劫持的案例
- 对于安全页面 (secure pages),确保其依赖项 (dependencies) 也是安全的
- 保持规范化信号 (canonical signals) 的明确性,避免模棱两可
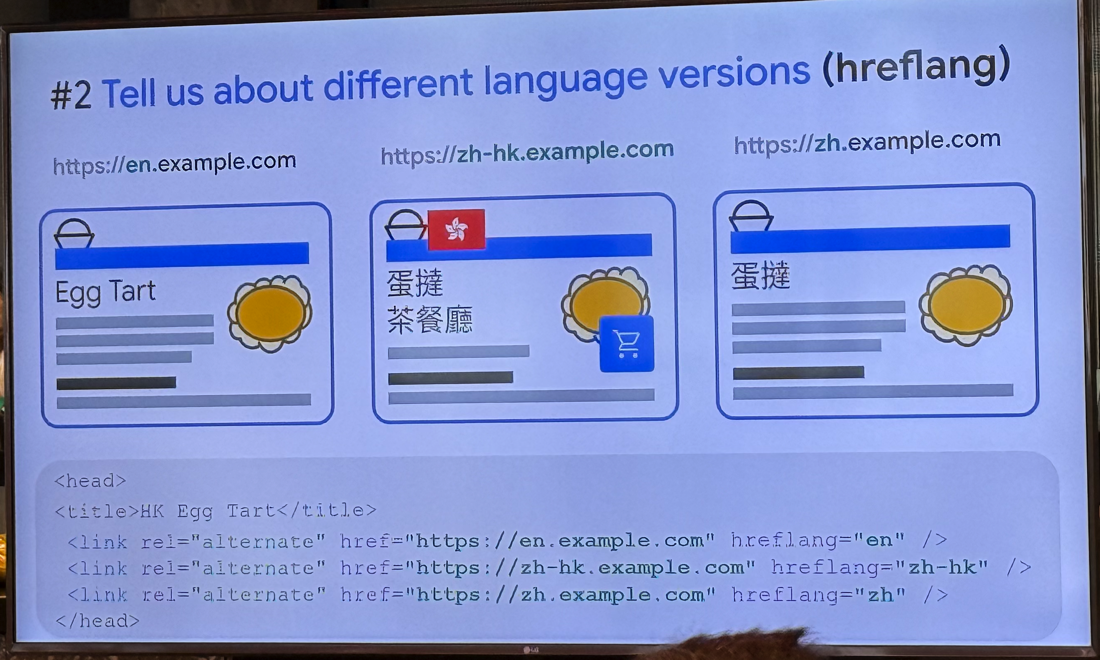
3. 语言、国家和域名(详见右图)
- Google不会通过hreflag或者HTML tag来判断网站语言,也不会通过URL的语言参数判断,而是用网站内容来判断语言
- 不同语言应该有不同URL且需区分语言,例子:语言-国家.域名.com zh-hk.example.com
- 不同国家地区的版本,用ccTLD会更好,如.com.au
- 语言网站的阐述需明显,文本和图片都需要为该语言
使用本地化URL:https://developers.google.com/search/docs/specialty/international/managing-multi-regional-sites
Pagination:https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
1. 相同内容的聚合



2. 官方建议

3. 语言、国家和域名










图片索引
1. 注意事项
- 如仅将内容放图片中,搜索引擎无法理解内容,图片的网址也需要被爬取到
- 假如不希望被爬取的文字或者图片,就用robots.txt来防止消耗爬取预算
- 图片可设置为large,因为discover的用户喜欢
2. 支持的图片格式
- Google 图片支持以下格式:AVIF、BMP、GIF、JPEG、PNG、WebP、SVG
- 最佳做法: 使用 AVIF 和 WebP 等高品质的现代格式,以在品质和压缩之间取得良好平衡。


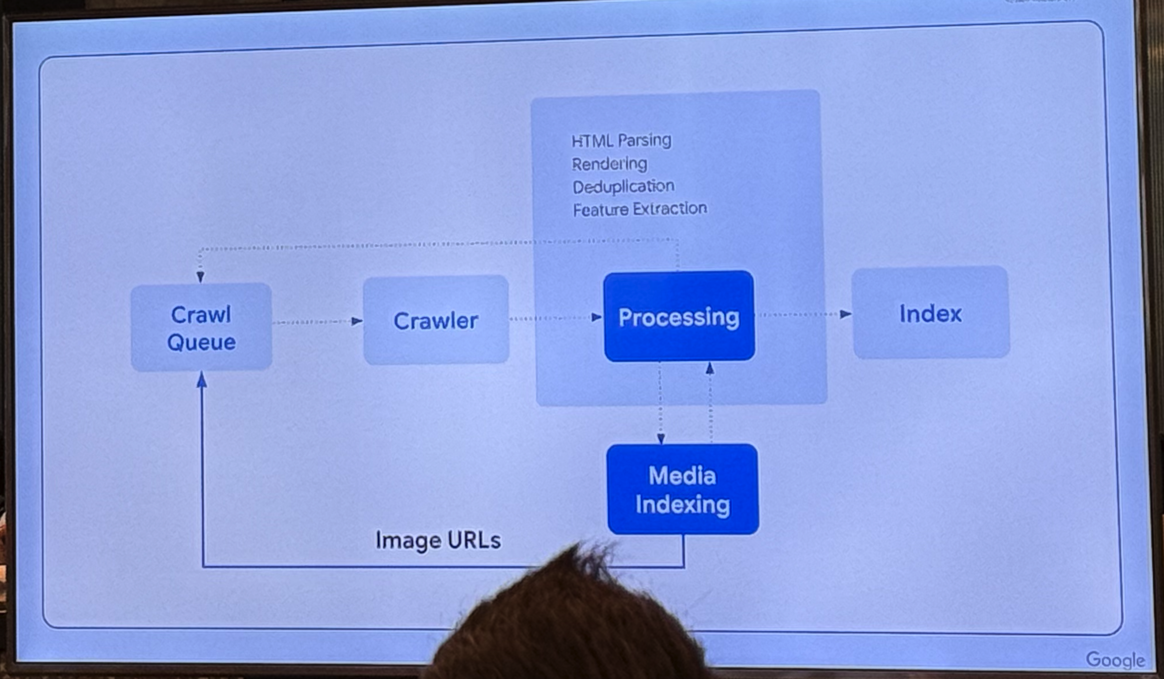




视频索引
1. 视频在SEO中的重要性
- 视频内容为王:用户对视频内容的偏好与日俱增
- 提高参与度:提高点击率、更长的页面停留时间以及更多的转化
- 更广泛的触及范围:能够吸引积极搜索视频内容的海量观众
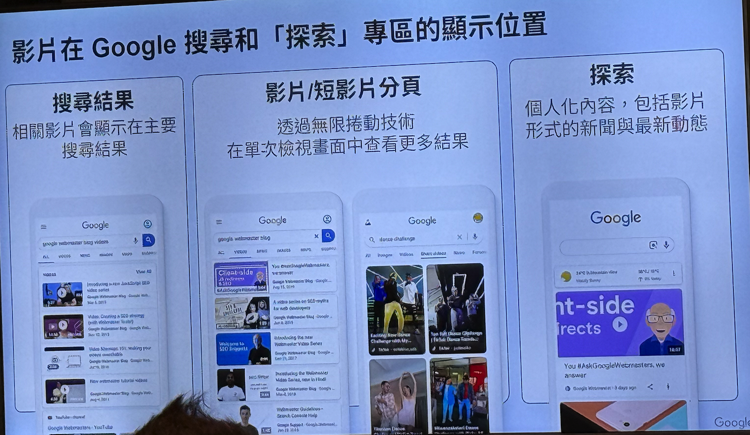
- Google 的整合搜索:视频会出现在Google综合搜索结果、图片搜索和专属的视频标签页中。
2. 视频SEO成功的关键因素
- 高品质视频内容: 引人入胜、内容丰富且制作精良的视频是基础
- 专属观看网页: 为视频创建专属的观看页面
- 吸引人的标题和说明: 针对搜索意图和用户点击进行优化
- 相关缩略图: 确保缩略图引人注目且能代表视频内容
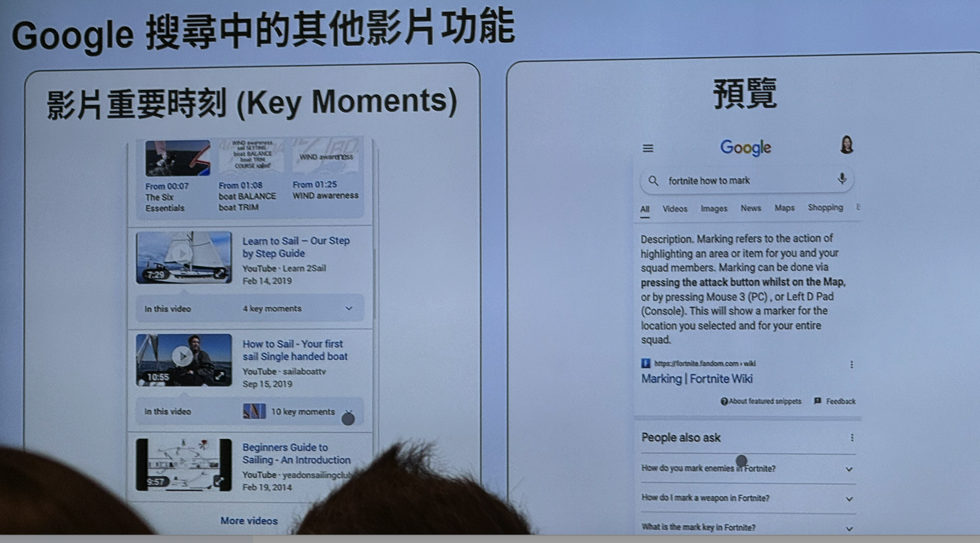
- 影片标记/结构化资料: 协助 Google 理解您的视频内容
- 快速载入网页: 确保嵌入视频的网页能够快速加载
- 加入 Sitemap (网站地图): 协助 Google 找到您所有的视频内容
3. 支持的视频格式
- 普遍支持的格式: MP4、MOV、AVI、WMV、MPEG、FLV、WebM、3GP。
- 最佳做法: MP4 与大多数浏览器和设备的兼容性最佳,因此通常建议使用这种格式
- 编码注意事项: 使用标准转码器(例如 MP4 采用 H.264)
4. 如何让 Google 更容易发现视频
- 以显眼的方式嵌入影片: 确保你的影片在页面上易于浏览,Search Console 会显示错误,方便排查
- 建立视频 Sitemap (网站地图): 协助 Google 找到所有的视频网址,尤其是嵌入式视频的网址
- 新增带有相关资讯(标题、说明、缩略图、播放网址)的 <video:video> 标记
- 在周围使用具有描述性的文字: 嵌入式影片周围的文字可提供背景资讯
- 考虑使用影片代管平台: YouTube、Vimeo 等都提供内置的探索功能
- 宣传影片: 透过社群媒体、电子邮件清单和其他管道分享
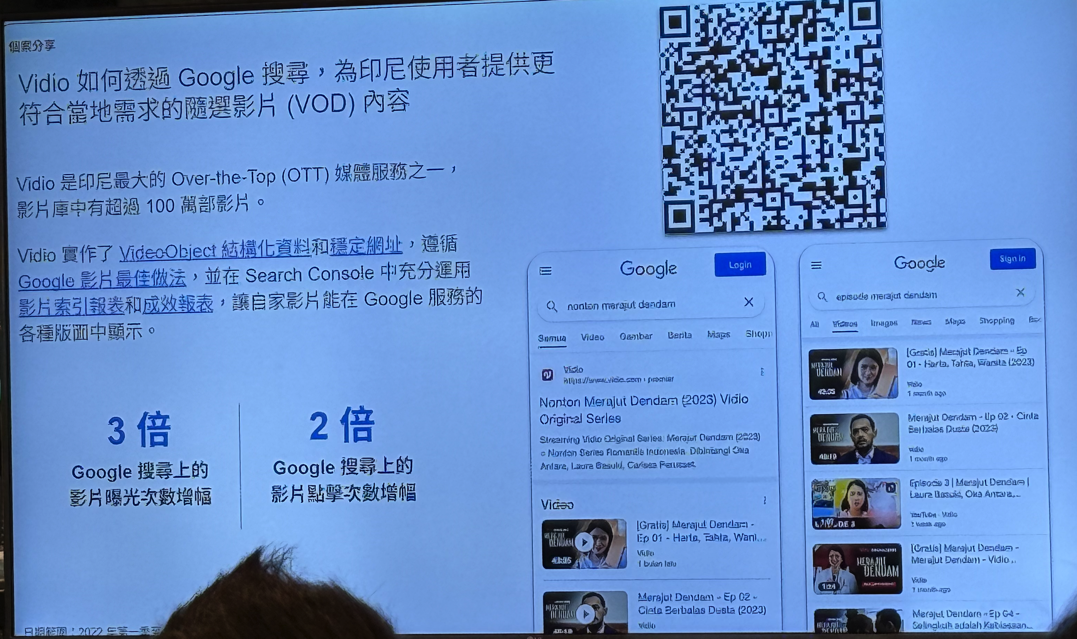
5. 案例:印尼视频平台Vidio
印尼视频平台Vidio如何生成video-on-demand(VOD)视频
https://developers.google.com/search/case-studies/vidio-case-study
6. 查看视频数据
Google Search Console → Indexing → Videos
https://support.google.com/webmasters/answer/9495631?hl=en
Google 搜索中的视频展示位



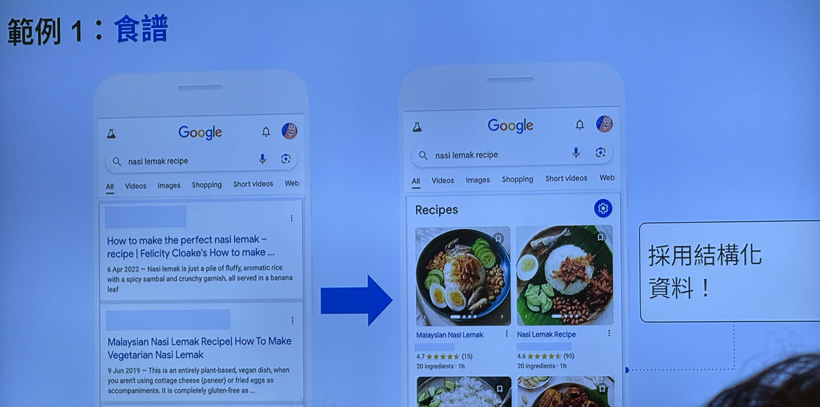
复合式搜索结果 Rich Results
1. 注意事项
- 不会直接影响排名:结构化资料不会直接提高你的排名,但可能会吸引更多使用者访问网站,间接带来正面影响
- 不保证结果:实施结构化资料并不能保证系统会显示你的复合式搜索结果。最终结果是由 Google 的算法决定。
- 无需结构化资料即可显示:有时不需要加入代码,Google 就能产生网站名称等复合式搜索结果
- 需要维护:这项工作并非一劳永逸,必须监控结构化资料是否有错误并持续更新
2. 测试效果
Rich result report overview:https://search.google.com/test/rich-results
测试链接:https://search.google.com/test/rich-results
分享产品数据指南:https://developers.google.com/search/docs/specialty/ecommerce/share-your-product-data-with-google
Google Search支持的结构化数据:https://developers.google.com/search/docs/appearance/structured-data/search-gallery

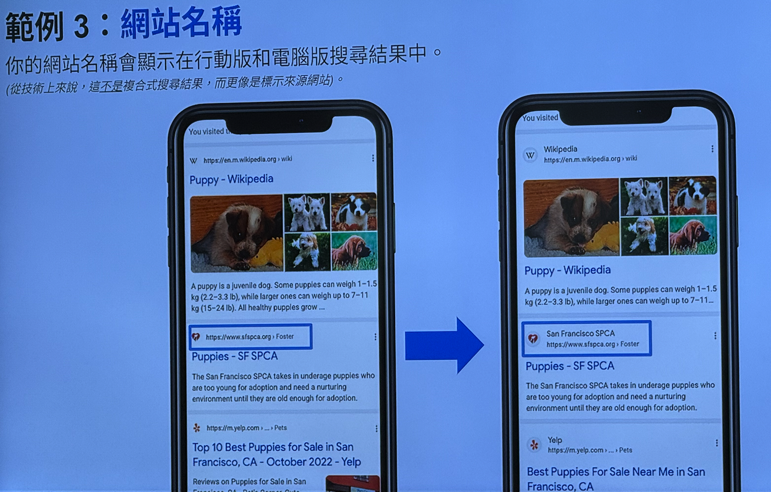
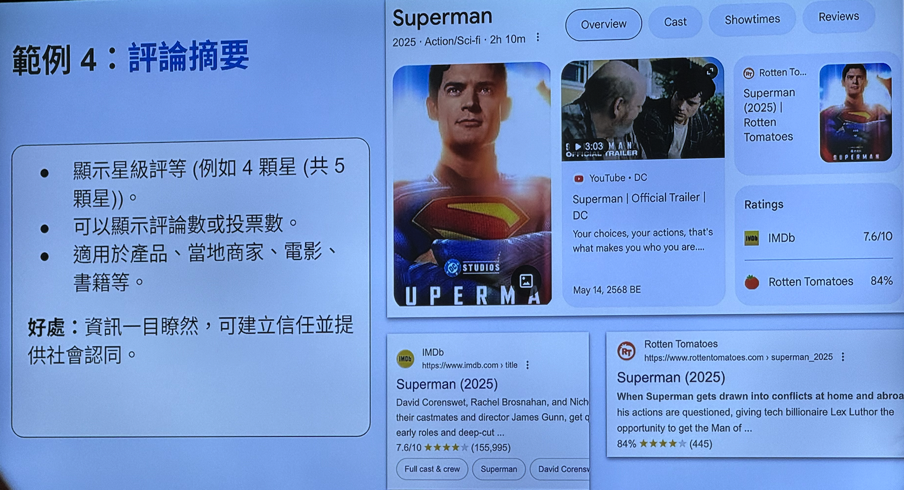
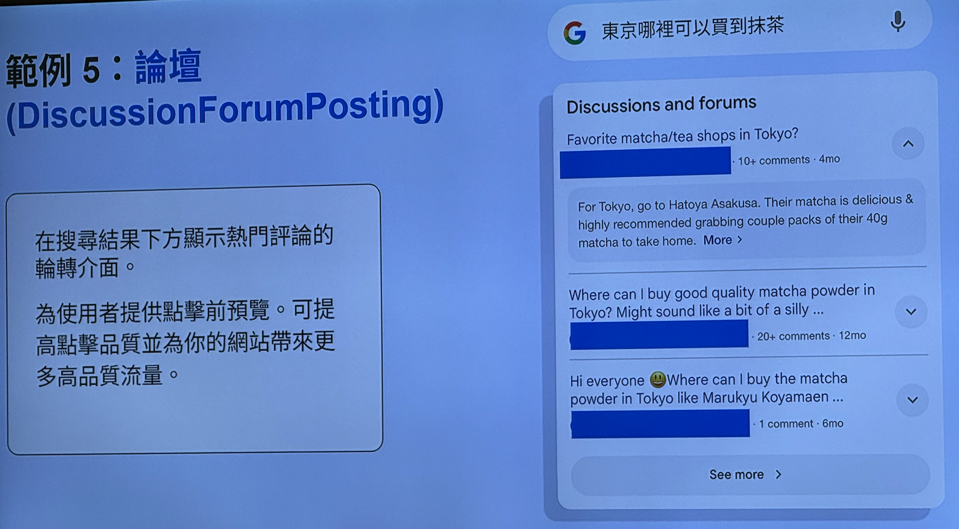

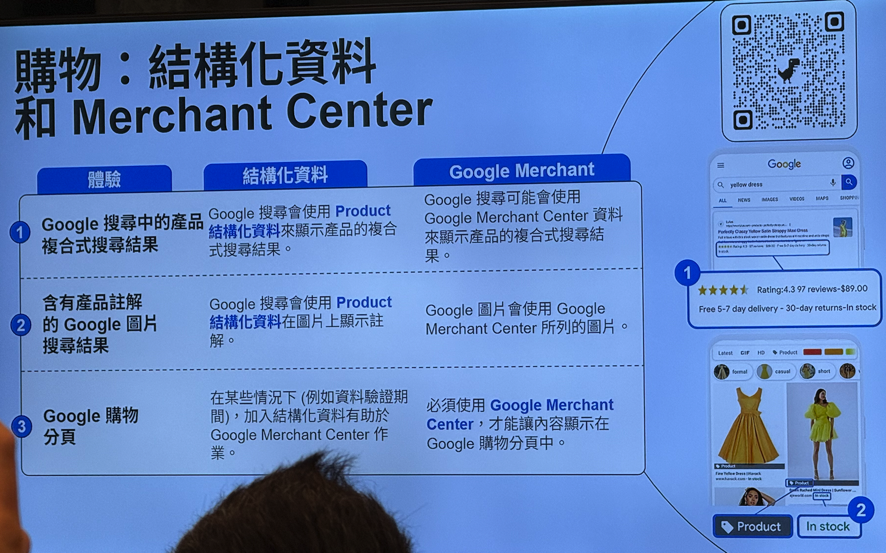
抓取预算 Crawl Budget
1. 抓取预算 = Crawl Rate Limit & Crawl Demand
- Crawl Rate Limit(抓取速率限制)是一个全站范围的指标,由所有谷歌抓取工具 (Google crawlers) 共享。主要驱动因素:
- 连接时间 (Connect time) 的变化
- 首字节时间 (Time to first byte) 的变化
- HTTP 429 或 5xx 状态码(即“请求过多”或服务器错误)
- 如果以上这些指标(即服务器问题)增加,
hostload(服务器负载)就会被调整,结果是谷歌的抓取速率将会减慢
2. 消耗抓取预算的因素
- 无限的 URL 空间 (Infinite URL spaces)
- 与服务器负载无关的服务器错误 (Server errors unrelated to server load)
- 无用的页面和资源 (Useless pages and resources)
“无限URL空间”或“无用页面”的示例,这些通常由URL参数(问号?后面的部分)生成:
- 日历 (Calendars) (例如: ?d=7&m=2&y=27)
- 产品过滤器 (Product filters) (例如: ?color=1&size=s)
- 版本化的资源 (Versioned resources) (例如: ?v=2537474)
同一个网页内容,但不同的url结构,会消耗爬取预算,只需告诉搜索引擎想让它爬取的内容链接
假如网站很小,没必要担心爬取预算,假如有1000+url就需要注意了
3. Crawl Budget VS HTTP Status Codes
List of HTTP status codes: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
HTTP状态码,反映网页状态:
- 1XX:不会影响爬取预算
- 2XX:成功,会消耗预算
- 3XX:跳转,会消耗预算per hop
- 4XX:错误,不会消耗预算
- 500:不能索引,会消耗预算
爬取频率不会影响某个URL或网站的排名



Honest Results Policy
Google不会为任何网站提供特殊待遇
https://search-off-the-record.libsyn.com/honestly-about-googles-honest-results-policy-and-more-0

官方报表模板
1. 排查 Google 搜索流量下降报表
Google 搜索如何运作(2)
https://developers.google.com/search/docs/monitor-debug/debugging-search-traffic-drops
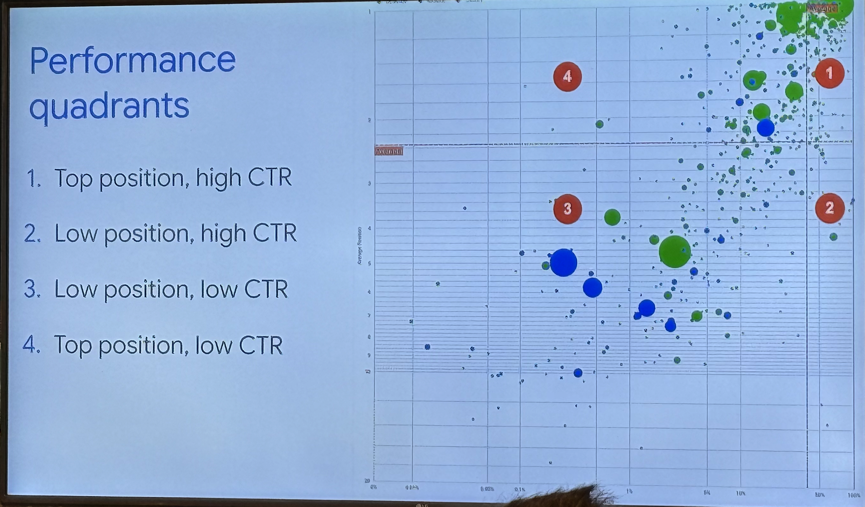
2. 利用 Search Console 气泡图优化 SEO
https://developers.google.com/search/docs/monitor-debug/bubble-chart-analysis
3. Google Trend教学系列
youtube.com/playlist?reload=9&list=PLKoqnv2vTMUO8MUpCbVIiBaDZYrpNF8f-
Google不介意内容是AI还是人工生成,只在乎是否高质量内容,是否真实和与用户的提问相关





