
文档阅读说明
这是一个独立项目启动的参考文档,他的阐述会偏简单,因为这是一个单薄,不够商业化的项目,仅供参考
我会在文章正文插播一些警告,用黄底标明,文章正文使用红底表示强调
这个项目前期是我一个人用AI做了18.5个小时(我不懂代码),基本流程都顺利完成了(完整实操流程在最后),但是要精细化优化的时候搞不定了,只能等我的开发从001项目腾出手再继续推进。
需求描述
在飞书上完成第一次写作与文档维护,称之为元数据内容。(正常需求不应该直接确定方案为飞书,应该根据需求定方案,但这个需求毕竟是我个人需求,请勿对号入座)
完成元数据内容后,成稿可以快速转换为各个平台的格式:公众号,知乎,即刻,小红书,Twitter,notion等
其中公众号是HTML格式
知乎,人人都是产品经理是,notion是异构的Markdown,
即刻,Twitter是短内容+图
小红书是图+文
这一步提升的效率是最高的,每次发布根据内容长度节约1~4小时时间
进一步地,内容格式可以快速定义修改更佳。(例如今天公众号用这个风格,明天用那个风格。)
- 这一步不提升效率,但会极大提升用户体验,没有人不需要个性化、美观的内容格式,千篇一律的格式看似解决问题,其实没有解决问题
进一步地,能做到一站式点击发布更佳
- 这一步提升的效率略低,在各类格式内容已完成的情况下,多平台发布大约节约10~30分钟时间
插播:警惕“我想要”,利用“我想要”
说实在的,不管用户要不要,我自己是肯定要的,我无法忍受我的效率浪费在编辑格式、搬运内容上面
这往往是很多点子来源:“我自己需要”,但一定要谨慎,我需要≠市场需求
但如果可以把握住“个人”与“用户”的结合,是一个非常棒方法,因为你就是需求的代表,你做的大部分决策都无需数据论证,仅凭直觉即可做出
所以,如果你有个点子来自于非常强烈的“我想要”。问自己三个问题:
我,有多少人?像我一样的用户规模有多大
我,愿不愿意付钱,如果愿意,做多付多少,平均付多少?
我,在哪里?我怎么触达他们?他们是聚集的吗?还是没有明确的聚集地点(指网上社群)?最低廉的触达渠道有哪些,哪些我能做哪些不能?哪些渠道即使这次不成功也应该尝试,以便积攒为下个项目的经验?
这三个问题用术语概括就是:需求规模,商业模式,流量渠道,三个问题答案不佳就枪毙这个点子
需求规模
背景判断
背景裁员潮,经济负面情绪,AI浪潮,推动了互联网群体为首的用户群更多进入自媒体行业(因为简单)
但视频、播客成本较大,更大的比例选择图文,纯文开启这条路
规模测算
基于人群画像测算
存量作者不能计算在内,他们可能已经有了习惯的平台,高超的公众号编辑技巧,
TwitterAI类中文博主的关注量级峰值在10W~20W左右,这部分用户可以视为潜在用户
随便找一下一些裁员新闻:24年上半年,阿里员工数量减少21098人,如果工夫再深一点可以翻翻23年,22年,21年,目前找到的数据大概是每年几万的量级。并且幸存的人也会更愿意考虑后路。
我们初步可以不精准判定,愿意投入写作,自媒体的潜在互联网人群,可能在20万量级,但潜力是潜力,是否会转化,即使转化又有多少会以飞书为第一阵地,是一个残酷的现实问题。
并且意愿是一方面,能力又是一方面。残酷地说,大多数人在有知识|有输出能力|有输出意愿|有输出变现方式这四个方面是很难都达到的。而如果他们无法在这个尝试中获益,对此类效率节约工具的付费意愿也会大大降低。——5W粉丝的博主愿意支付100元/月乃至更多,但刚起步的新手不可能。
基于相似产品测算
赛博禅心的飞书转公众号,24/11/2日发布,阅读2.7万,265点赞,点赞率1.7%。公众号排版器飞书插件官方飞书文档阅读人数1489人,反馈群467人。
卡茨克的公众号转其他插件,24/11月20日,阅读2.6万,1162点赞,点赞率4.4%
爱贝壳同步助手Chrom插件,插件显示用户量1000,官方飞书文档创建日期9月21日,阅读人数2365人,推测1500人左右
结论
结论一:整体的潜在用户规模时很大的,但这只是上限,需要考虑时间,考虑需求强度
结论二:公众号是更多的人的首选阵地,常识判断如此,卡茨克VS赛博的数据也能佐证
结论三:在当前,用户规模在1500~2500人之间,并且具备付费意愿的用户会进一步降低。
推测:无意外情况,需求规模在1年内都会很难突破1万人。如果进一步对官方文档的日新增访问人数进行一段时间的统计,对这个数值可以更加精确(这个需求不值得,我只是给个思路)
补充
如果你做的是其他需求,还有更多的测算手段
APP可以去APPmagic看下载量(免费),可以去点点数据看新增评论量,看搜索指数热度
做PC网站肯定也有各种方法,我还没开始做这个,就不瞎推荐了,去看哥飞的内容
甚至你可以将你的Idea做成说明书,做成视频发出来,根据社媒声量判断需求大小(这次我用的就是把立项报告拿出来,看看需求规模是不是如想象的那么小)
一定要想方设法测算,越直接,越真实的推测越好,别信行业报告,很多都是实习生做出来的
商业模式
竞品定价参考
爱贝壳,5元/月,限制次数,限制同步数量。VIP添加路径访问70次,推测付费率4.6%~10%之间
公众号排版器,免费
卡茨克公众号转其他插件,免费赠送
传统H5编辑器是8元/月,不含模板等额外付费选项
如果你做的是别的需求,这一步很简单,把所有相似产品的定价方案抄下来,列个表格
成本定价方法
规则转换,样式渲染等,0成本。在用户本地调用资源进行。
图片不分,初判0成本。可以借用免费图床服务,且由于所有图片只是中转,不会保持太久,故也不会产生图片储存费用。
自定义格式,每次调用claudeToken2000,成本0.1元/次。具体成本需Demo跑通后矫正
获取飞书文档的元数据,如通过服务器中转,以5000中文/次,3张图片/次,成本大约大约$0.00000008(通过GPT初步咨询,需后续校正)

内容各站一键发布,0成本。通过用户本地资源进行。
人力成本
原型设计,UI设计,预计2小时内完成
代码部分,项目不涉及复杂逻辑,基本上各个模块线性调用,预计28小时人力内完成(如我自己用Cursor,此时间X3~10)。
算法部分,Prompt模板调制预计3小时内完成
运营部分,教程官方文档预计1小时内完成。
时薪600,一次性投入在20400~54000~171600元(程序员写→我CursorX3→我CursorX10)
结论
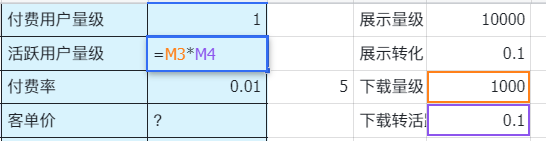
参考前述信息,整个市场的营收参考线为2000用户*10%付费率*5元定价=1000元/月,最低投入20400元计回本周期在20个月(和餐饮有的一拼,6)
更正确的方案是列出一个动态函数表格,而且指标也要比例子中的更丰富,可能包括营收、付费、流量、下载率、转换率、各类均摊成本等等,互相之间用函数联动。不用担心你定的成本,付费率错误,不断获得更好的信源不断更正就行,当然最好的信源就是MVP上线。

流量渠道
如果你是知名博主
你可以自己推荐产品,也获得其他博主的推荐,会有客观的冷启动流量
你可以用影响力作为背书获得官方合作,例如飞书社区工作人员
所以这就是目前为什么连雷军都在做自媒体IP的原因,流量太贵了,而自媒体是最廉价的流量
如果你不是知名博主
目前的CPM可以参考为10~50,不同赛道之间会有很大差异,你可以先拿这个参考线,再套进去下载率,转活率,付费率算算能不能打平。很多时候打不平还得妥协地继续算LTV,能算LTV的就至少是个正规生意了,小生意别用LTV去欺骗自己。
根据人群去找流量:前置分析中包括飞书/AI/互联网/裁员这些关键词,去即刻、小红书尝试起号介绍拿免费流量。其中即刻可以视为零碎社区,零碎社区小众用户群体更容易被找到,而小红书可以视为宽泛社区,小众群体淹没在大众声音中,推荐算法可能会让你爆点,但更大可能是淹没你的故事。
寻找病毒营销可能性:这个产品不一定能走这个方案,因为他的故事在11月已经被消耗了两次。你不再能讲“全新推出,独一无二”,你只能讲“痛点改造,全面升级”。一方面很弱,另一方面这种故事最好是建立在痛点人群规模很大的情况下才行,现在整个用户规模才几千,不是特别有用。
建议
能做自媒体做自媒体,做自媒体可以比创业优先级更高
如果非常非常小众的需求,去垂直社区更好。但只要是中等规模,例如记账、学习等,小红书这类平台更好。
DAY1就要考虑你的产品怎么传播,有些传播不是依靠内容的,而是依靠功能设计的。例如在这个产品里面,如果能够录制一个视频,便捷快速地将飞书内容进行拆解,然后转化成为小红书图文,那么他的视觉冲击力,引爆点概率是要远远高于“自定义修改样式”这个需求的。那么可能他的优先级就更加的高。不熟悉这种思路的可以看看黑客增长相关的书,里面有很多例子。
产品设计方案
假设你是不懂代码通过Cursor开发,建议先写好产品设计方案,并且这个方案的字数、细节程度必须至少是以下内容的十倍。然后带着产品方案与AI再进行你的开发。
从飞书导出元格式内容
- 如果有哪里搞不明白,可以询问飞书挂载的机器人,还挺好用的
开通权限
- 开通飞书开放平台权限,并开通查询各类文档接口的权限,参考这个项目feishu2MD
身份鉴权
在调用上述接口的时候,是需要进行Token鉴权——即你是谁,你有什么资格来获取数据
可以用应用鉴权和用户鉴权,我先用应用鉴权试一下:
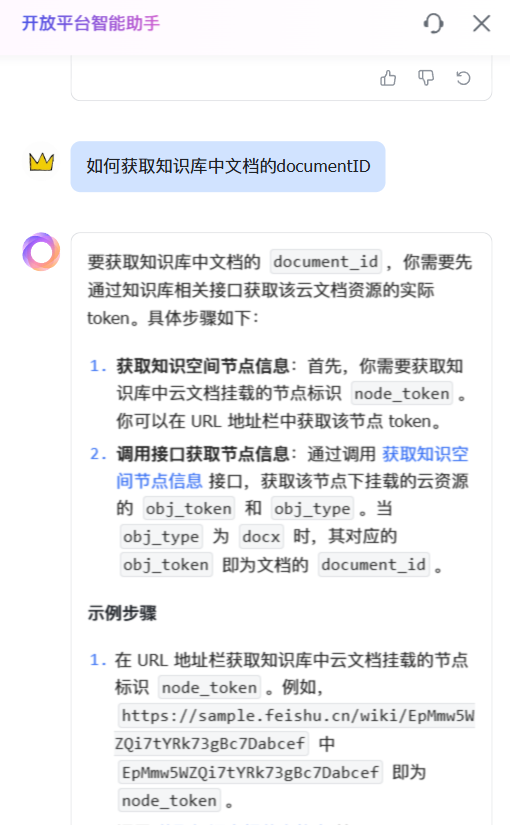
获取文档唯一标识
- 通过飞书分享链接解析出云文档唯一标识符,例如这个文档的唯一标识就是“TjZEwOXKCiI78Uk3dg6ce9Venah”,在链接中很容易分辨,可以让claude写一个简单的正则匹配判断
将文档唯一标识转为documentID
如果是知识库中的文档,要先通过接口获得知识库中云文档对应的doucumenid,这个才是真正的唯一标识符
如果是非知识库中的文档,唯一标识符就是documentID
基于documentID获取所有内容块
开发代码映射规则
飞书的内容样式太多了,很多是我写作根本不会用到的,全部纳入进去会超出上下文,也会做大量无用功

做一个样式样例文档,获取后只关注我会用到的样式就行了
通过claude完成飞书样式→公众号样式的转换模板
小红书的图文,知乎的MD格式,Twitter等的短文案需要另外设定格式,先做公众号这个流程
自定义代码样式
要求claude将样式转换模板做成可配置的
可以针对每种飞书样式自由定义对应的公众号样式,例如一级标题,可以是黄色字体也可以是红色,甚至可以是带着黑色边框的
对应的自定义样式,一种做法是直接在前端做AIcoding功能,一种是预留输入框,用户可以自己写或者在其他地方完成转换后填入。目前采用第二种方案
一站式批量同步
- 网页登录对应公众号后,通过反向代理和RPA工作,实现同步,这个需求先不做,通过爱贝壳实现就行了
流程性需求
政策考虑
合规
如果服务开设在国内,claude无法使用,同时需要域名备案,需要走通企业支付路径,需要更多精力调试语言国内模型是否支持相关能力。即使支持,也需要走算法备案。
如果服务开设国外,只服务非大陆用户,那么用户规模会进一步锐减,但应该不会减少太多。
对接
如果是个人自用,飞书开发平台的接口个人账号即可开通
如果要做线上服务,就必须使用注册公司对接飞书,才能以插件方式进入插件商店
实现记录
总结
共计投入18.5个小时,随着项目复杂度的上升,不得不提前终止“完全基于AI开发”,接下来会把这个项目转交给我的专职程序员继续。在整个AI开发过程中有如下发现:
上下文看似制约,其实不是制约的本质,因为真正的项目其复杂度是远超2万甚至200万Token上线的。所以当我从windsurf和Cursor切换到cliine,并拉满上下文后,确实短期解决了项目的瓶颈,推进了一大步,但终究无法应对越来越膨胀的代码。真正的制约是你能否有效管理项目中的各类概念,并井井有条地向AI分配任务。但如果你能做到,你就不是小白呀?
AI coding不仅仅需要需求描述清楚,更需要清楚的是代码逻辑。所以小白一般在刚开始最快乐,在中间能稍微解决,在后期逐渐崩溃。因为小白真的对各类概念一无所知。看起来是一个“为什么文字底部不能加色块”的问题,会衍生类、CSS、HTML渲染、JS执行等等一系列陌生的概念,你会发现技术的学习还是绕不开。
AI很擅长后端逻辑,因为他是清晰,明确的,我花在后端上的实际差不多仅占1/10。但AI不擅长UI、样式,因为这是和人的审美相关的。偏偏审美又是模糊的,很容易陷入甲方的五彩斑斓黑陷阱。
在终端选择上,我只用过Cursor,windsurf,cline。windsurf交互体验比Cursor好,但这两个都是订阅制,都会千方百计减少上下文记忆以节约成本。cline交互没那么好,但可以全量上下文ALLin,就是太贵了。14个小时烧了我15美金。
AI在处理小需求小项目的时候仍然很值得信赖,爬虫、批量化、数据分析等等,依旧可以解决大量重复性工作。
如果你一定要硬撑着用AI完成一个中等规模复杂度的项目。那么建议你同步学习代码,先搞懂逻辑,然后试图读懂代码,磨刀不误砍柴工,这样绝对,绝对比你黑灯瞎火对着AI指挥要来得快。当然这个过程一定很痛苦。
最后是一些普世的使用建议:有进展了,千万用Git随手保存 | 尽可能各个能力封装模块化 | 有较大更新后让他写进Readme中,后面可以拿这个给他看 | 一开始可以说复杂需求,后续尽可能一次描述一个小需求 | 邀请他追问细节 | 认真阅读他的每一步操作,不求看懂代码,至少看懂逻辑 | 可以让他在敲代码前先给出分析和逻辑说明,也可以让他在有更新后写入Readme,这些都可以放到预置的Prompt里 | 提前思考好你的项目逻辑(我指技术实现部分),在外部文档上敲下来,而不是在打开AIcoding的那一刻才开始思考。
24年12月21号(4小时)
立项文档协作+信息搜集,3小时左右
阅读飞书官方文档并注册验证,1小时左右
24年12月21号 (3.5小时)
22:00 开始敲代码咯~(展开可看完整Prompt)
plain text我要实现一个产品功能,将飞书文档导出后转化为微信公众号HTML样式,小红书图文格式等 先描述飞书→公众号的需求细节: # 第一步,解析飞书链接中的文档在知识库中的标识Token - 例如:https://whjlnspmd6.feishu.cn/wiki/TjZEwOXKCiI78Uk3dg6ce9Venah?from=from_copylink,其中“TjZEwOXKCiI78Uk3dg6ce9Venah”这部分就是标识Token # 第二步,调用飞书接口,获得查询接口的tenant_access_token,请求示例如下: curl -i -X POST 'https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal' \ -H 'Content-Type: application/json' \ -d '{ "app_id": "这个ID我后面会填", "app_secret": "这个秘钥我后面会填" }' # 第三步,调用飞书接口,查询这个标识Token对应的documentID,请求示例如下: - 请求示例 curl -i -X GET 'https://open.feishu.cn/open-apis/wiki/v2/spaces/get_node?obj_type=wiki&token=这里是标识Token' \ -H 'Authorization: Bearer 这里是tenant_access_token' - 返回中的obj_token就是documentID,返回示例如下: { "code": 0, "data": { "node": { "creator": "ou_be387b5cb2b942224d5169cf2706cf8d", "has_child": false, "node_create_time": "1734787759", "node_creator": "ou_be387b5cb2b942224d5169cf2706cf8d", "node_token": "Ojz0wCo4aieUf1k4KmYcujOxn7d", "node_type": "origin", "obj_create_time": "1734787759", "obj_edit_time": "1734787968", "obj_token": "后面填", "obj_type": "docx", "origin_node_token": "Ojz0wCo4aieUf1k4KmYcujOxn7d", "origin_space_id": "7222693585387290625", "owner": "ou_be387b5cb2b942224d5169cf2706cf8d", "parent_node_token": "TjZEwOXKCiI78Uk3dg6ce9Venah", "space_id": "7222693585387290625", "title": "飞书写作-常用样式文档" } }, "msg": "success" } # 第四步,调用飞书接口,通过documentID拉取飞书的所有内容块,请求示例如下: curl -i -X GET 'https://open.feishu.cn/open-apis/docx/v1/documents/这里填documentID/blocks?document_revision_id=-1&page_size=500' \ -H 'Authorization: Bearer 这里是tenant_access_token' 返回后的json结果请保存到我的本地路径下:D:\6self\feishu\outputjason,命名以标识Token为命名 # 后续步骤(这个需求不需要你实现,仅供你提前进行预留设计) 加载第四步获得的jason文件,通过公众号样式转换模板,转换为公众号样式,公众号样式模板要求如下: - 首先你要定义公众号样式的整体风格,例如背景颜色,页边距等 - 其次你需要将每个飞书样式转化为对应公众号的HTML样式,例如飞书的一级标题,到了公众号就要变成绿色的20号字体 - 但是这个需求你先不用做,我只是提前和你说一下,因为我会在后续和你对清楚飞书的内容样式具体是什么格式 # 扩展功能(这个需求不需要你实现,仅供你提前进行预留设计) - 支持自定义转换样式:我需要你支持我对公众号整体样式风格,飞书的每一种样式提供配置能力,我可以在未来自由修改希望转换成的样式风格 - 支持公众号以外的样式转换,例如知乎、小红书等,你需要预留这种功能切换的能力,不要写死为只支持公众号样式转换 # UI界面 - 初始状态下最中间有一个输入框,可以输入飞书链接,旁边有个解析按钮,点击后你执行一二三四步以及样式转换步骤。 - 解析后在左侧显示飞书文档的导出内容,右侧显示经过样式转换后的公众号样式 - 在右侧的公众号样式预览窗口上方,提供一个复制按钮,我可以复制渲染后的公众号HTML样式,直接贴入微信公众号后台完成发布。 # 要求 1. 用Node.js 语言完成这项需求 2. 先完成第一,二,三,四步,以及UI界面 3. 所有代码都要写清楚注释,我是一个完全不懂代码的小白,非常依赖你的注释来理解代码逻辑 4. 请帮我把整个项目的结构先预留实现好,然后尽可能把代码分割为模块,不要耦合到一起,方便修改和排查问题 现在开始吧,加油22:46 windsurf什么东西,给了目录结构,但是无法帮我创建……是什么权限没拿到吗,蛋疼
23:00 秀儿,原来是什么系统策略不允许执行本地脚本,我还一个个手动创建了这些文件,服气,程序员做的东西真的不顾小白生死啊
23:04 跑起来了,成功完成一二三四步,抓到飞书原始文档了
23:07 开心了一下继续
plain text很好,还记得我们之前说的步骤吗? 先拿到飞书文档的元数据,然后我会给你看飞书样式内容的格式定义,然后由你制作公众号样式转换模板 我们先来看飞书的样式内容定义 @飞书样式定义.json 我们结合起来一起摸清这个样式定义,然后你把这个样式定义写成一个文档存到项目代码中,方便调用 这一步我们只做这个事情,我们可以沟通多轮,但要保证理解一致对齐,而且因为样式内容太多了,做太多我怕你后面由于大模型上下文长度导致遗忘 # 飞书的样式文档有很多引用,请梳理好结构保存,例如这个例子: Text 页面、文本、一到九级标题、无序列表、有序列表、代码块、待办事项块的内容实体。支持多种样式和元素。可容纳 TextStyle 和 TextElement。 { "style": object(TextStyle), "elements": [](TextElement) } 名称数据类型属性默认值描述 styleobject(TextStyle)optional-文本样式。详见 TextStyle 的数据结构。 elementsarray(TextElement)required-文本元素。详见 TextElement 的数据结构。23:30 节点崩了,我TM,下班
24:00 节点好了,继续
plain text@飞书样式样例.json 你看看这个我导出来的示例文件,是否里面的内容你都能识别,以确保我们已经覆盖了所有样式的定义 为了以防超过上下文长度你看不见内容,你要告诉我你看到这个文件的最后一个段落是什么00:04 发现漏了图片的样式定义,进行了补充
c++图片块的属性我们补充进去,其余两个先忽略 Image 图片块的内容实体。了解如何插入图片块,参考常见问题-如何插入图片。 { "token": string, "width": int, "height": int } 名称 数据类型 属性 默认值 描述 token string optional - 图片 Token,只读属性。 width int optional 100 图片宽度,单位为像素。 height int optional 100 图片高度,单位为像素。 align int optional 2 对齐方式。详情参考 Align 枚举。00:10 感觉有点不安,问了一下git这个东西怎么用,我之前只知道能做代码的版本管理,不知道具体是怎么一回事
c++我是一个新手小白,我现在要怎么进行代码的版本管理呢?是用git吗? 请列出完整清晰的步骤,包括且不限于安装,注册,配置,提交操作细节,关键概念等等,这些只是我的举例,请当我是一个五年级的小学生向我提供引导方案00:21 开始进行公众号样式转换模板开发
c++非常棒,现在我们进行下一步工作,把导出来的飞书内容,按照我们之前讨论的样式文件,转换为对应的公众号HTML样式。 # 样式转换要求 - 你要定义好整体的样式风格,包括且不限于整个页面的背景颜色,两端缩进等 - 将飞书所有样式一一转写为公众号对应的HTML样式(记得预留配置功能,我后续需要对这些样式做自定义修改) - 你可以定义一个模板号的概念,例如A模板是这种风格,B模板是那种风格 # 执行要求 - 你现在先输出一个模板风格,要求风格简洁,类似苹果的设计理念,采用黑白配色 - 记得把之前的UI设计关联上,前面我们UI界面上右侧的公众号是没有转写内容的,只有读取的飞书元内容,这次要加上转写样式后的内容,而且不要放源代码,要放渲染过的结果,这样我可以点击复制按钮直接粘贴走00:33 熟悉的噩梦开始出现了,修改了一个需求,然后开始报BUG,打开F12把问题截图给它,搞不定我要回滚了
01:06 不知道为什么,总之BUG解决了,现在是他识别东西丢三落四了,果然解决完一个BUG还有一个BUG
c++你看看样例文档的转换结果,存在问题的 # 第一种,内容出来了,但是样式没有生成对应的样式 1. 字体的颜色,背景颜色你根本没有实现,可以参照“正文带颜色带背景”这一条内容 2. 引用样式,你只是一个普通的正文字体,也没有转换成一个常见的引用样式(前面加一个灰色的竖条那种) 3. 链接样式,也是普通正文,没有链接的蓝色,也可不点击 4. 高亮块,也是普通正文 # 第二种,你甚至连内容本身都弄丢了,完全消失 1. 有序列表 2. 无序列表 3. 分割线 4. TODO01:18 开始暴躁,口吐芬芳
c++你修改啥?样式定义文档一共286行,为什么你看完前100行就要动手?01:25 程序员老婆告诉我,用npm run dev 就可以不用每次像windsurf说的一样,杀掉服务又重启了,WTF!
01:47 绝望,回滚版本,睡觉
24年12月22日(11小时=早3+午4+晚4)
09:14 开始干活
10:47 卡住了,一直无法识别飞书导出的json,看不懂代码不知道哪里出错了,windsurf/Cursor都试了,搞不定,很大一个挑战在上下文上,这类封装好的AIcoding上下文是黑洞,你不知道他是不懂,还是上下文信息太少乱搞。换成cline+3.5sonet,打满上下文
12:32 cline烧了超过5美金,现在基本跑通了。一开始不懂怎么用,就让他自动循环,屏幕代码自动跑像黑客一样,酷是酷,全是Token在燃烧。后来搞明白了,一条条问,控制好上下文,很快解决问题。
html现在大部分样式转换已经正常了,但是复制HTML贴到微信公众号后台的时候粘贴进去的却是html源代码 我看有一些MD转微信公众号格式 是可以直接粘贴进微信公众号后台的,而且保留了预览时候的样式,这是怎么做到的你知道吗14:14 继续搞,现在只差3个问题:图片没有获取,调出来的当前样式不好看,公众号预览宽度不对,先解决图片问题,不想看文档,直接问飞书AI,原来是获得图片ID后,通过素材接口下载
html我导出了飞书的所有内容块,但是图片中没有包含图片URL,我要怎么获取飞书文档(在知识库中的文档)内的图片URL呢14:53 之前偷懒出问题了现在,鉴权方式用的应用鉴权而不是个人用户鉴权,现在应用没有下载素材的权限。当然也不能全怪我,飞书让我开的权限我都开了,但就是不行,估计又要在这里堵一会儿了
14:59 很奇怪的逻辑,各种内容块都能获取了,就是素材不行,还要添加为协作者,算了照做:官方文档;题外话,通过图片Token拼接飞书链接好像能直接下载,那我为什么要走那么复杂的授权方案呢?
15:01 问题解决了,我服了,现在开始写获取图片的代码
html接下来,我们把飞书的图片下载下来,他这个逻辑有点特殊,因为导出的飞书json内容中image是不提供URL的,我们需要通过图片Token再调用相关接口下载图片 在做样式转换额时候这个类型的内容块要做特别处理 # 第一步,解析出图片Token 在导出的内容块中,图片Token位置在image下的Token字段,如下面这个例子: { "block_id": "BZ7FdboxIoaWjHxqlfDcKAGPnSe", "block_type": 27, "image": { "align": 2, "height": 640, "token": "Vtj3bzOY6oQirExWB99cuN9Nntd", //这个就是图片Token "width": 640 }, "parent_id": "IZPJd0qvWoJFGXx96Pccu3wpnZb" }, # 第二步,调用接口下载图片 - 请求示例 curl -i -X GET 'https://open.feishu.cn/open-apis/drive/v1/medias/这里填图片Token/download' \ -H 'Authorization: Bearer 这里填tenant_access_token' - 接口返回一个二进制文件流,需要下载下来,并将文件名重命名为“图片Token” # 第三步,把下载的图片上传到亚马逊S3,获取URL - 上传亚马逊S3必要的信息如下: AWS_ACCESS_KEY_ID=后续填 AWS_SECRET_ACCESS_KEY=后续填 AWS_REGION=后续填 AWS_S3_BUCKET=后续填 - 这一块我不太熟,如果还需要我补充一些信息请告诉15:59 链路通了,但是微信公众号不支持海外亚马逊S3服务……本来想偷懒借用现成服务的,现在得去开通一个国内亚马逊了。这个不支持本质上是S3没有配置好相关信息,感谢@也树提供的帮助
17:43 搞不定,这个领域太陌生了,实例、IAM、权限、储存策略等等等,都是我没接触过的概念,已经在这上面卡了快2个小时了,先跳过这个问题。
17:44 开始做多模板的公众号样式
18:22 放弃多模板公众号样式,还是先手工调整,随着代码规模越来越大,操作越来越难,就像用20米长的筷子伸进黑箱里,凭借触觉反馈摆出八卦阵图案一样。
18:33文档太大的话,会超过素材下载的QPS限制,添加QPS限制模式
19:18 开始优化公众号样式
html@/src/styles/wechat-template-a.js 请给这文档每行代码都添加相应注释 我打算对这个微信公众号模板进行优化,我需要看懂这里面的每一行代码是在干嘛23:20 4个小时了,卡在样式这里4个小时了,烧了20美金了,毫无进展……下班!
这种感觉就像蒙着眼睛,拿着筷子,夹起玻璃杯堆金字塔,只能靠手上的反馈来操作,随着项目规模膨胀,筷子长度还会从1米变成10米,20米,太糟糕了。
问题清单
样式转换支持自定义样式(倒在这个问题面前…卡了我4个小时)
公众号后台,无法拉取亚马逊美区S3图片
只支持了自己常用的一些样式,还有一些没支持,例如表格
飞书中图片只有Token没有URL,需要接口下载公众号预览宽度不对