6.2 系统水平分层
分层的目的是水平隔离复杂性,那么怎么定义"一层"呢?由于对具体分层的定义非常模糊,导致了我们实际上分了很多层,但是却觉得没几层。
架构分层的主客体分析
互联网通信依赖的网络协议 TCP/IP 是一个非常经典的分层模型,因为全球网络是一个经典的分布式系统,实际上我们无论在设计哪种形态的分布式架构都可以参考网络协议的设计思想。
我们在学习 TCP/IP 或者 OSI 分层网络时会使用一个常见的"邮差"比喻,来形象的描述网络协议的原理,其中就体现了分层的思想。
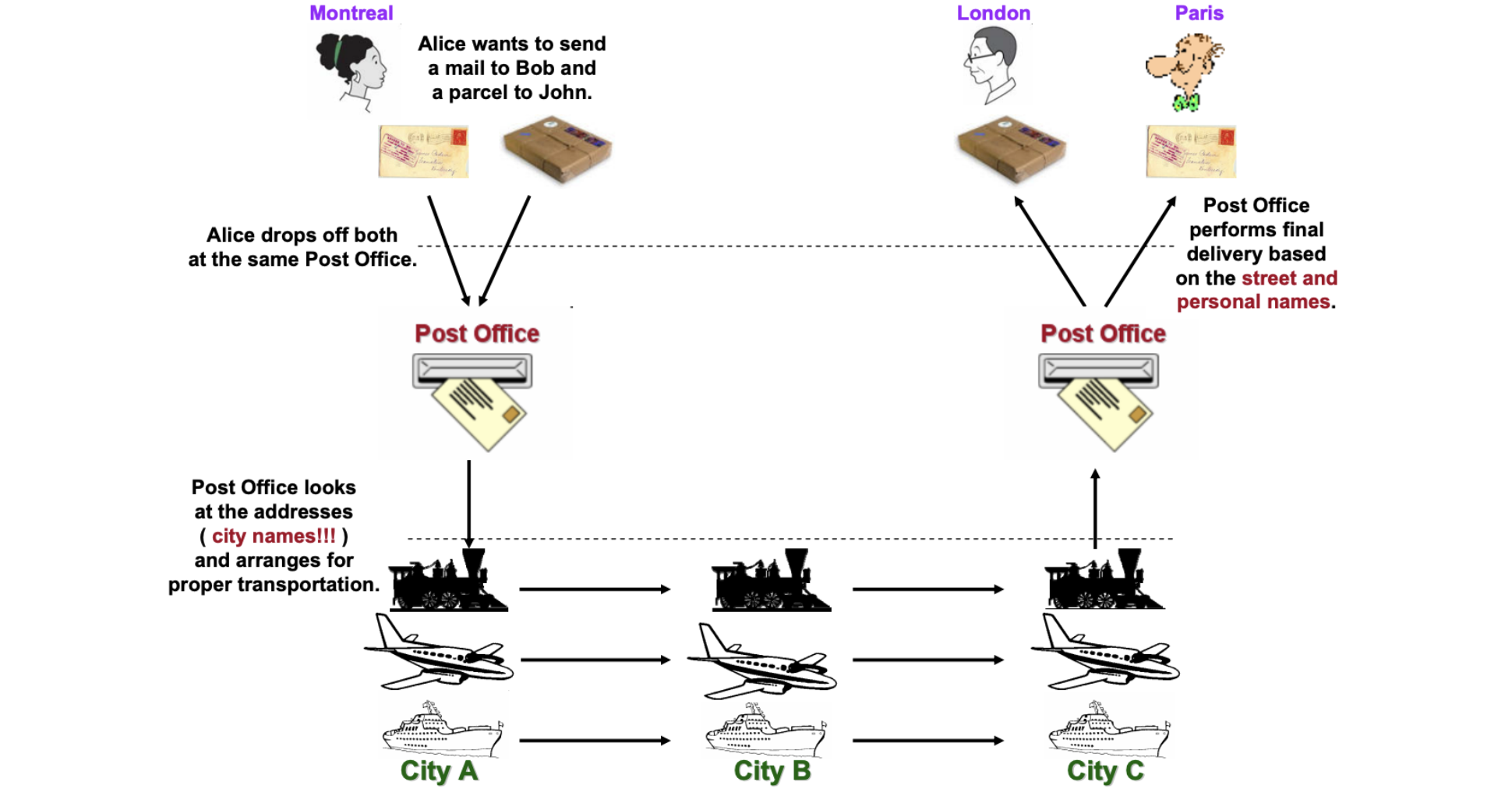
Montreal 需要寄送一个信,她在信的结尾写上了自己的名字作为落款,然后通过邮局将其寄出。邮局进一步包装贴上邮局的标签,并发送到运输公司。运输公司将其装箱,并通过不同的交通工具将其递交到目标的站点,并发送到目标邮局,也就是他们在目的地方的客户那里。最终,邮局将信件发送到收信人手中。
我们将整个过程看做三层:用户层,也就是收信人、发信人收发信件的过程;邮局层:邮局的工作人员处理邮件的过程;运输层:物流公司通过不同的交通工具运输货物的过程。
有时候,我们仅仅通过行为来描述分层很难说清楚分层是什么,比如邮局和物流公司的分层在某些情况下可能说不明白。我们可以通过另外一个视角来看待这个问题。
图片来源:https://www.eecs.yorku.ca/course_archive/2010-11/F/3213/CSE3213_03_LayeredArchitecture_F2010.pdf
任何一个行为都能找到它的操作者以及身份,也就是行为的主体,也能找到被操作的内容,也就是行为的客体。我们可以通过分析主体、行为、客体三个要素来辨析分层之间的关系。这样让分层更加明确。如果能在该层找到明确的主体对象、客体对象,并说明其关系,我们就能将其说清楚。
我们用一张表格来划分,并将其表述地更加精确:
| 主体 | 行为 | 客体 | |
|---|---|---|---|
| 用户层 | 收信人、发信人 | 收发信件的过程 | 原始信件 |
| 揽收层 | 邮局、揽收点 | 揽收寄件,并打包的过程 | 包装后信件 |
| 运输层 | 物流公司 | 运输货物,装箱运输的过程 | 物流箱 |
通过主体的明确和客体的明确,主体之间的职责会清晰地浮现出来,主体的权责更加清晰,我们细心分析也会发现这种分层也是社会化分工的体现。主体的性质是截然不同的,邮局、揽收点作为法律主体时,一般不是以自然人的性质出现的。另外物流公司这类主体往往也需要额外的资质、营业许可,侧面的说明了分层的要素。
这是现实中的分层思想,那么在软件中是不是这样的呢?假设以后端业务系统的经典三层结构作为例子,我们来看下它的分层主客体分析:
| 主体 | 行为 | 客体 | |
|---|---|---|---|
| Controller 层 | Controller | 处理业务场景 | Request/Response |
| Service 层 | Service | 处理通用能力 | Model |
| Repository 层 | Repository | 处理数据持久化 | 数据/SQL |
用主客体来分析,MVC 模型如果没有 Service 时,只能算两层,因为 Model 只是客体(忽略 Model 和其属性之间的主客关系),构不成完整的一层。Service、Repository 层都有对应的主客体关系,能够说清楚它的权责关系。
如果按照网络协议的分层设计,下层是不需要知道上层的信息或者知识的,也就是说理想的情况下 Repository 层的客体应该是无差别的数据才对。所以我们可以看到 JPA 这类 ORM 工具接收了两类参数:数据体 + 领域模型的类型信息。当我们无法实现出无差别的 Repository 层时,才不得不使用持久化对象这类概念。
所以这里总结下对分层的理解:
- 分层是主体权责的让渡,通过分层演化出更多主体,实现分工。
- 下层需要尽可能地提供无差别的能力给到上层,让上层对下层保持透明。
那么通过辨析主客体的关系,就能提高代码的表达力,尤其是在命名上。所以对客体起名的关键在于定义这个客体的概念,使用拟物的方式起名。对主体的起名需要定义它的职责,使用拟物的方式起名。
这样就能通过类似"主谓宾补"(主语:服务对象,谓语:方法,宾语:参数,补语:返回值)的方式编写代码,让我们在编写业务代码时思绪流畅。
应用和服务分离
良好组织代码的关键不是将方法划得足够小,而是对象各司其职。 架构的本质就是将各种库、业务代码、基础设施等架构的组成部分良好的组织到一起,这是在成为架构师的路上必须想通的一环。企业架构框架把信息架构分为四层:业务架构、应用架构、数据架构和技术架构。如何把业务系统中的代码良好的组织起来,就是我们应用架构中的内容。
应用和服务分离 是一个非常简单的原则,在各个地方都有体现,但是没有编程大师像 SOLID 原则一样明确的表述出来,但它又很重要,能给我们一个如何复用代码的准则。
"复用就一定好吗?"
当我向同事问出这个问题的时候,同事一脸茫然,好像软件开发本来就应该这样,所有的代码都应该尽可能的复用。
复用,在多数人的眼里已经是理所当然了,但有时候还是忍不住提醒一下,复用只是手段而非目的。
复用是通过消除重复代码的方式,得到一系列可以重用的代码片段,在需要的地方组合使用即可,提高开发速度的同时,也可以提高整体的一致性。
显然,组合组件用的胶水代码是不需要复用的,因为组合本身就是为了解决场景中的事情,不再具有复用价值。强行复用的后果有两个:
- 场景特有的东西被纳入组件,导致组件的复用性降低。信息被泄露到组件中,组件和场景中的代码职责不清晰
- 响应业务变化的能力反而降低了,说白了就是不好改。
有时候两段代码虽然看起来只有细微的差异,但是也不要复用它们。对于全栈开发者来说,这个原则对我们设计前后端的代码都有好处。在后端,我们可以使用 DDD 分层中的 application 让代码变得更清晰;在前端,我们可以将业务组件分为 pages 和 components 提升设计。
我们知道,在Eric DDD 的分层架构中,将系统分为了 4 层:
- 接入层(Interface)。
- 应用层(Application)。
- 领域层(Domain)。
- 基础设施层(Infrastructure)。
我们可以这样看待应用层:
应用层的目的是处理不同应用场景的差异,它被用于不同场景的关注点分离中。例如,用户下单可能会涉及多个原子的操作,订单、支付、积分累积等逻辑。
思考一个问题,为什么 DDD 中引入了一个应用层。没有它我们会面临什么问题?
如果缺乏应用层(在很多微服务系统中都是这样的),导致领域服务和场景绑定,复用性大大降低。例如系统接受用户自己注册,也可以使用微信登录完成一个隐藏的用户注册。另外一个例子,对于新用户,系统会为他赠送一些积分,在没有应用层的情况下,服务被前端直接调用,于是服务不得不定义来自不同渠道的 API。在下面的示例中,微信自动登录会比浏览器注册多好一些内容。
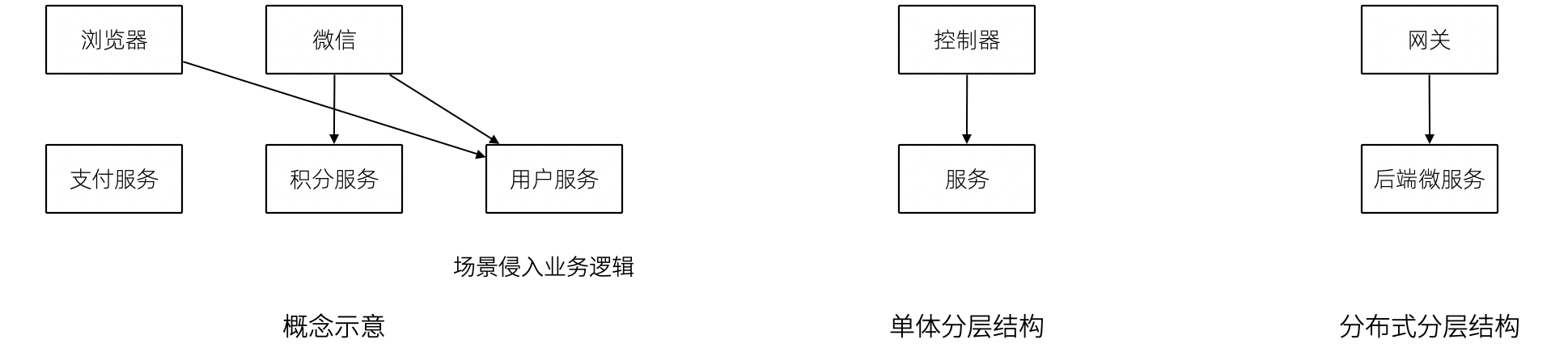
在一些情况下,大家只是把这层当做一个简单的代理,大量的和场景相关的逻辑进入了领域层,依然会为系统带来麻烦。
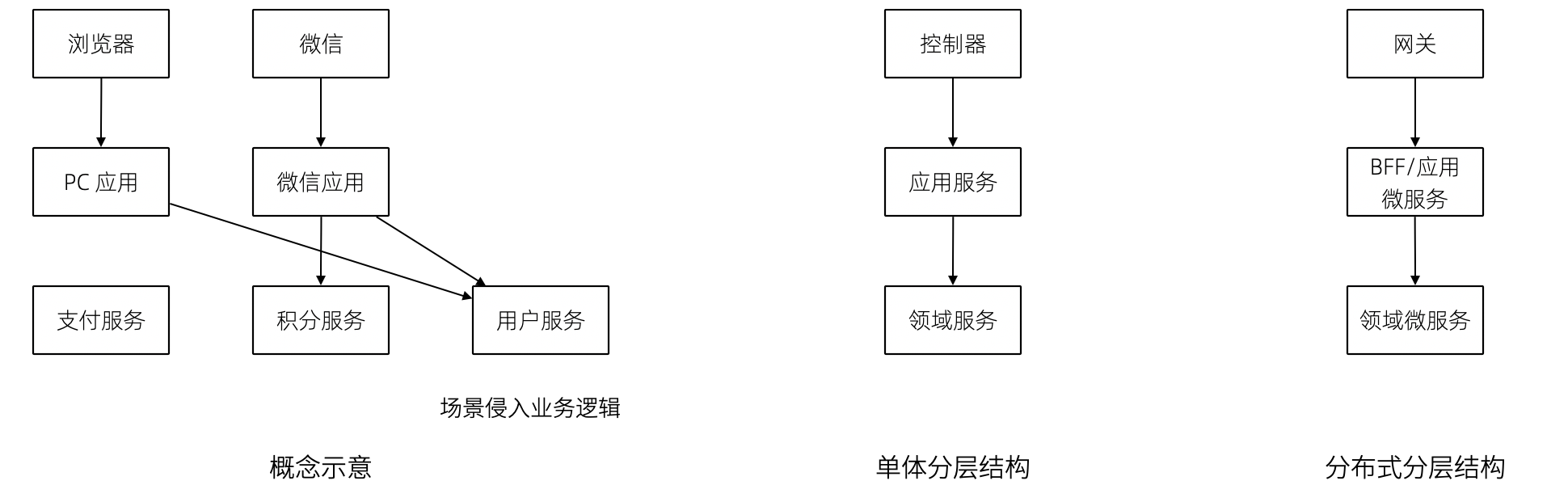
我们重新思考应用层,它到底解决了什么问题呢?
有一个典型的场景,就是管理员和普通用户,在使用场景的差异非常大,看似是具有不同的权限的同一个操作其实未必是同一个用例。例如,用户能通过 API 获得商品列表,管理员能看到未发布的产品列表。对于没有经验的工程师往往会编写一个 API 然后通过一些权限机制来限制它们的访问。
注意,这不是权限的区别!这是用例的区别。
管理员查看商品列表是一个用例,用户查看商品列表是另外一个用例。当我们不再把用例混淆的时候,就能理解应用层了。我们重新看待应用层和领域层两个层次的定位:
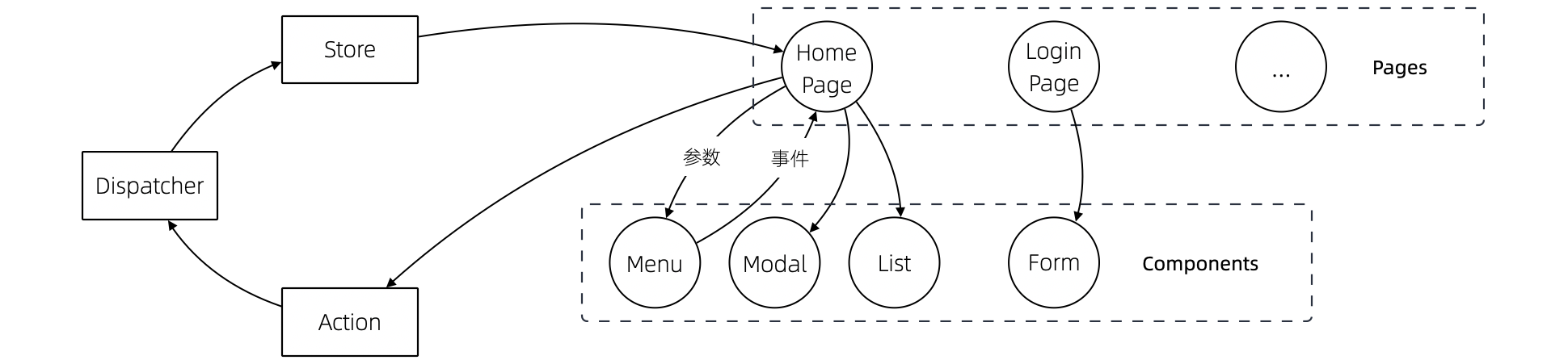
当我们能把每层的的职责弄清楚之后,代码的组织变的如此清晰,而在此之前我们还在靠把代码划分的更小来实现的。在前端开发中,随着工程化的发展,开发者把组件划分的越来越小的时候,也会有类似的问题。下图表达了 Store 模式的数据流动关系,对应的实现有 Redux、Vuex。
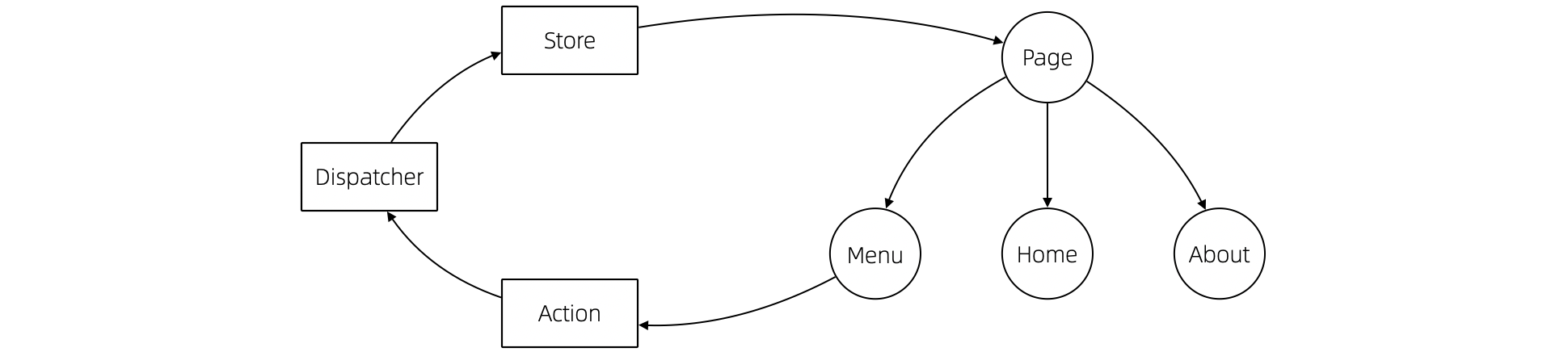
从技术的角度看,它的逻辑非常清晰,但是在实际的工程项目中会有一点小问题。
Action 的发生是从 Menu 等这些基础组件中发出的,也就意味者,Menu 组件和全局的状态联系到一起,这个时候 Menu 组件的复用性就降低了。
换个例子,设计一种弹窗组件,这个弹窗组件和全局的 Store 数据联系到一起的话,如果想要做到基础的组件在各个地方干净的使用,那么状态的承接工作就不应该由基础组件来完成。
我经历过几个项目,设计者没有意识到这个问题,带来的后果就是,组件为了复用不得不写很多条件语句。比如模态弹窗不得不使用枚举来区分是那个用途的弹窗。
问题的关键同 "应用和服务分离" 类似。如果页面用于承载状态,组件用于复用,那么两种组件具有了清晰地定位:
水平划分的权责
服务划分是职责划分的问题,职责划分的问题是权责利的问题。权责利是管理的基本思想,从这个角度上来看,架构设计和管理并无差别。
我们拿几个更具体的例子来说。在一次架构评审会议上,有一个问题大家争执不休,问题的背景是这样的:
在这个案例中,我们不妨问这样一个问题。我们为什么需要封装一个鉴权服务?
原因很简单,需要有专门的人来维护这个服务,并提供相应的能力。直接连接 Redis 会将这份工作让渡给了各个微服务,而不是 Redis 集群的运维团队,毕竟 Redis 集群的运维团队的职责只是提供 Key-Value 数据的存储,而与具体的业务无关。
如果将工作给了各个微服务,也就意味着 Redis 集群的使用权公开了,鉴权工作的考核(利)也分摊了。慢慢的,这个 Redis 集群会变成一个多方共管地区,会有更多的无关数据被写入,也变得危险和不稳定。
将鉴权服务封装起来的目的是权责利的隔离,封装成服务只是手段。这样看来,只要目的达到了,手段可以是多种多样的。我们可以考虑让一个团队构建一个 SDK 来提供会话数据访问的能力,这样既能满足权责利要求,也能避免一次网络通信,提高性能。
还有另外一个例子。我们在规划一个分销系统,分销系统会涉及组织结构、商品维护、订单流转、仓库库存、结算等多个上下文。这里就会出现一个矛盾,订单流转和库存之间会有强烈的耦合,如果将其合并可以减少分布式事务、频繁的跨服务调用的问题。但是,将其合并后,仓库库存和订单流转之间耦合了。
为了清晰地理解这个矛盾,我们可以回到现实中。订单流转是订货、发货方两个销售主体之间的关系,但是物流是基于仓库来说的,仓库是货物的主体。
从职权关系上来说,订单的流转和仓库库存之间的职权是不同的。我们可以将其微服务想象为一个虚拟的电子助手,这个电子助手应该能提供相应的能力,自然也需要承担责任,同时有权利访问对应的数据。
那么拆开后分布式事务怎么看待呢?
在现实世界中,如果交易的双方在地理位置上处于相同的位置,自然可以一手交钱一手交货。如果不幸的是,不能当面交易,只能通过书信或者电话远程交易,当交易发起后,其中任何一方返回就会产生冲突。
回到计算机世界,并不需要惧怕分布式事务。让最终一致性的收敛速度足够快,就可以看做强一致性。虽然我们应该尽可能的避免分布式事务,但是作为分布式系统应该坦然的接纳分布式事务的存在。不过需要警惕,无论技术上多先进,收敛速度多快,都会在一定几率上发生冲突。这也并不是大的问题,只需要人工的干预即可。